class: center, middle # Bias-Variance Tradeoff CS534 - Machine Learning Yubin Park, PhD --- class: center, middle Complex model <i>vs.</i> Simple model Which way to go? Bias-Variance Framework can provide some guidance --- class: center, middle Consider a system $$ y = g(\mathbf{x}) + \epsilon $$ where `\(\text{E}[\epsilon] = 0\)` and `\(\text{Var}[\epsilon] = \sigma^2 \)` --- ## Notations Assume that we generate a finite number of samples from this system. `\(\text{E}[\cdot]\)`: [Expectation](https://en.wikipedia.org/wiki/Expected_value) operator. e.g. `\(\text{E}[y]\)` is the expected value of `\(y\)`. `\(\text{Var}[\cdot]\)`: [Variance](https://en.wikipedia.org/wiki/Variance) operator. `\(g\)`: True model `\(f\)`: Our model trained on **finite** samples `\(\text{E}[f]\)`: Expectation of `\(f\)`. In other words, `\(f\)` trained on **infinite** samples. `\(\text{Var}[f]\)`: Variance of `\(f\)`. In other words, the variability of `\(f\)` due to the sampling nature. Note `\(\text{Var}[f] = \text{E}[f^2] - \text{E}[f]^2\)` `\(\text{E}[(y-f)^2]\)`: Expected error. NOTE that this is not the same as training or test errors. --- class: center, middle $$\text{E}[(y-f)^2] = \text{E}[(g + \epsilon - f + \text{E}[f] - \text{E}[f])^2] $$ $$ = \text{E}[((g- \text{E}[f]) + (\text{E}[f]- f) + \epsilon)^2]$$ $$ = \text{E}[(g- \text{E}[f])^2] + \text{E}[(\text{E}[f]- f))^2] + \text{E}[\epsilon^2]$$ $$ = \text{Bias}[f]^2 + \text{Var}[f] + \sigma^2 $$ The error consists of Bias, Variance, and Irreducible Error. --- ## What is Bias? $$ \text{Bias}[f] = g- \text{E}[f] $$ **Bias** is the difference between the true model, `\(g\)`, and the (theoretical) best-case of our model, `\(\text{E}[f]\)` For example, consider `\(g(x) = \exp(x)\)`, while `\(f(x) = \sum_{k=0}^K \beta_k x^k\)`. As finite-degree polynomial functions cannot behave like exponential functions, there will be always some gap between the true and our models. This theoretical gap is called "bias". Bias is related to the expressibility (or representational capacity) of a model. In general, simpler models have higher bias. --- ## What is Variance? $$ \text{Var}[f] = \text{E}[(\text{E}[f]- f))^2] $$ **Variance** is the variability of our model due to the sampling nature of the data. For example, the coefficients, `\(\beta\)`, of a linear model will vary depending on selected samples. The degree of such variability is called the variance. In other words, our model has high variance if our model changes a lot with inclusion/exlusion of data samples. NOTE that we are measuring the variability against the expectation of our model, not the true model. In general, simpler models have less variance. --- class: center, middle Conceptually something like this? .figure-350[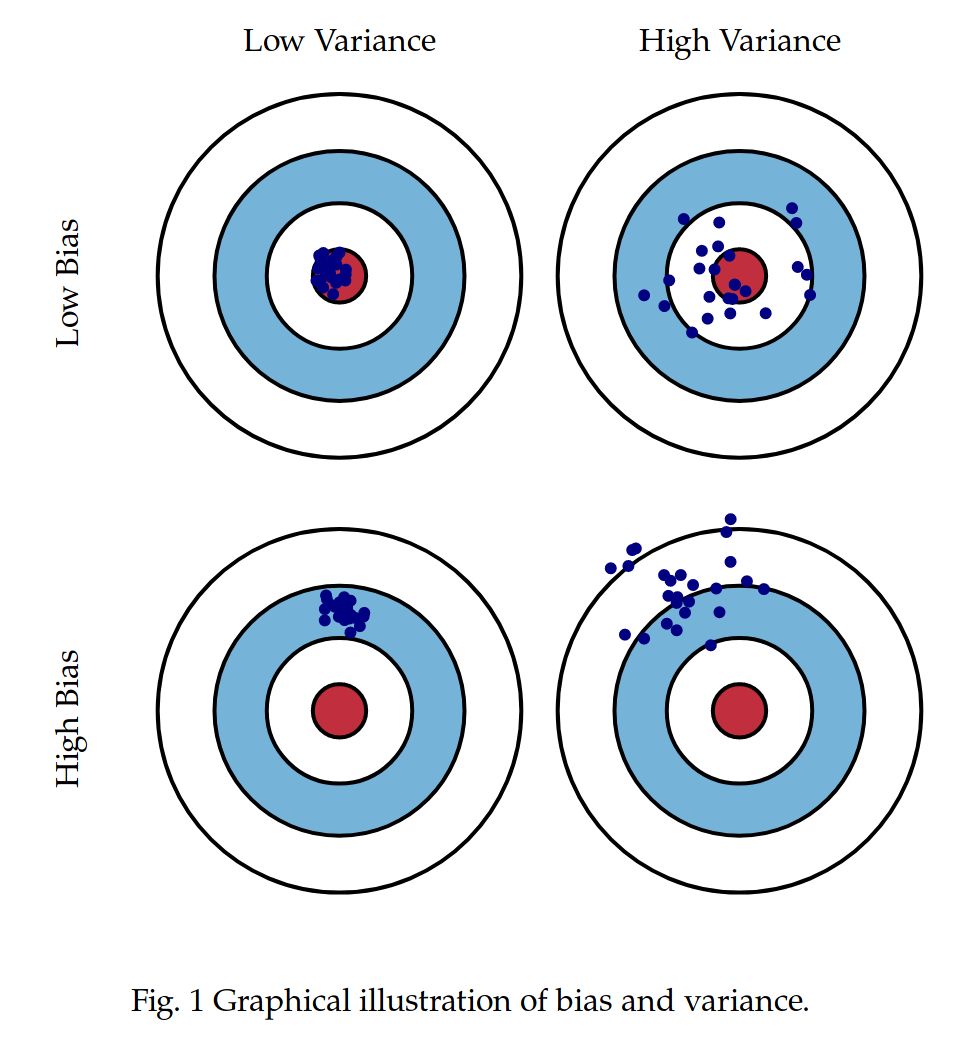] .reference[http://scott.fortmann-roe.com/docs/BiasVariance.html] --- class: center, middle Model Complexity and Bias-Variance .figure-350[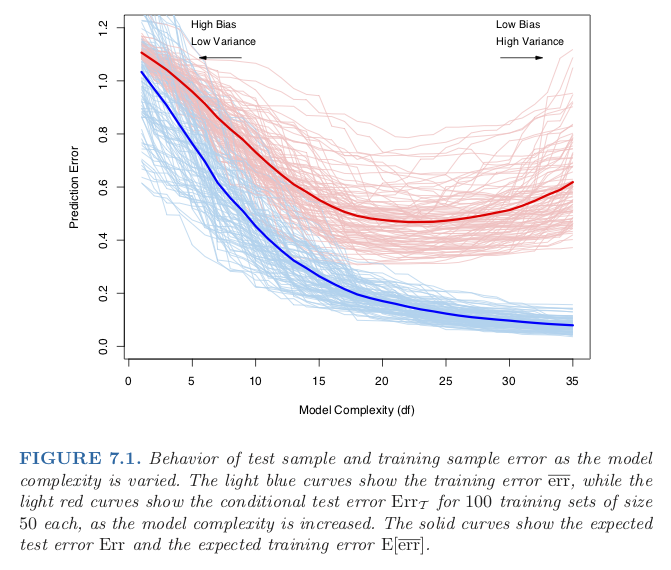] .reference[Chapter 7 of https://web.stanford.edu/~hastie/ElemStatLearn/] --- class: center, middle Why Shrinkage Models can be Better? .figure-350[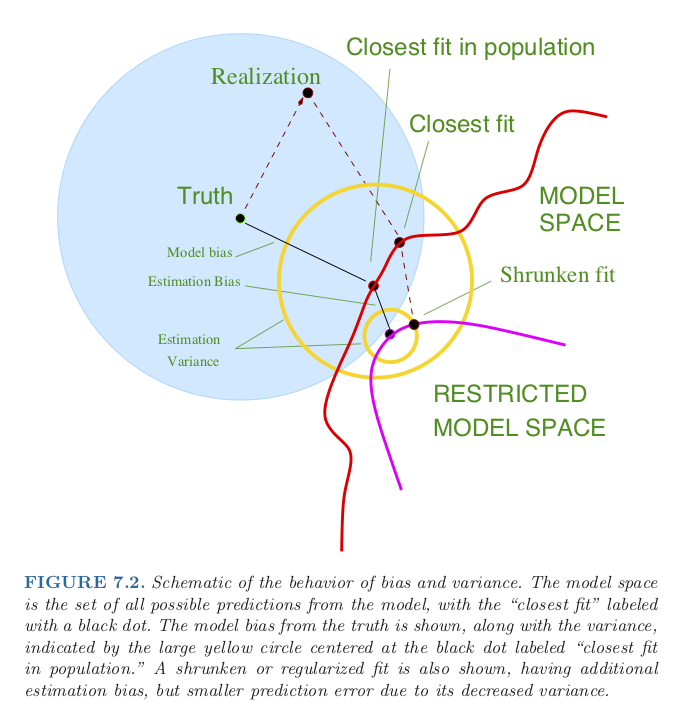] .reference[Chapter 7 of https://web.stanford.edu/~hastie/ElemStatLearn/] --- class: center, middle Overfitting vs. Underfitting .figure-w650[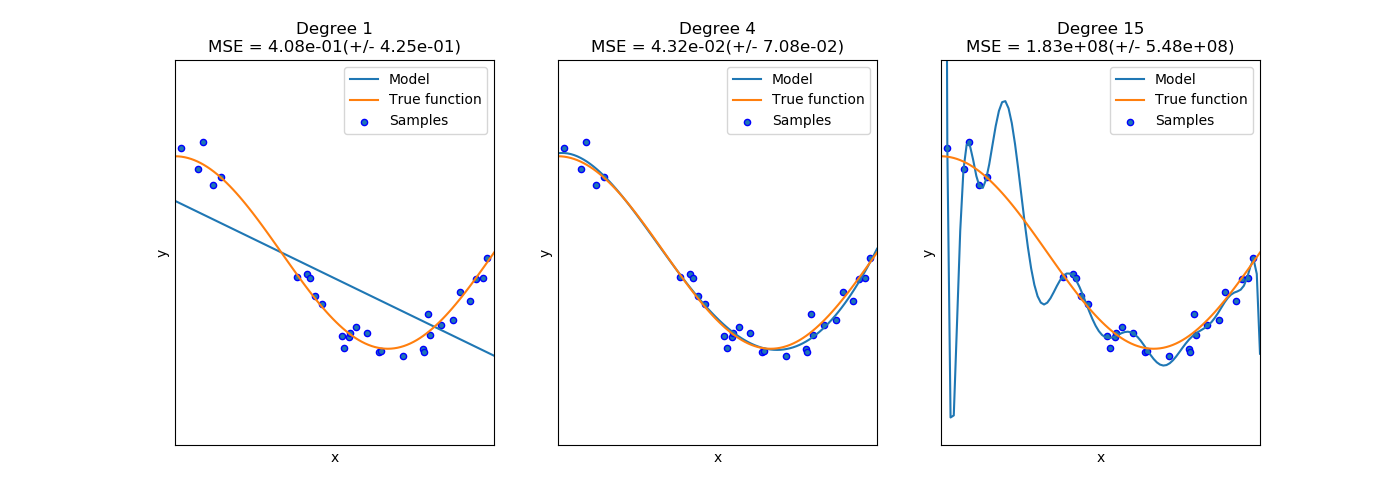] Underfitting (left most) = High Bias Overfitting (right most) = High Variance .reference[https://scikit-learn.org/stable/auto_examples/model_selection/plot_underfitting_overfitting.html] --- class: center, middle Assume the Irreducible Error is very small and the size of training data is fairly large. $$ \text{Bias}^2 = \text{E}[(g - \text{E}[f])^2]$$ $$ \approx \text{Average}[ (y - f)^2 ]$$ $$ = \text{Training Error} $$ --- class: center, middle Assume our model is complex enough $$ \text{i.e. }\text{E}[f] = g $$ and the Irreducible Error is ver small and also the size of test data is fairly large. $$ \text{Variance} = E[(f - \text{E}[f])^2]$$ $$ \approx \text{Average}[(y - f)^2]$$ $$ = \text{Test Error} $$ --- class: center, middle How to Use the Bias-Variance .figure-300[] .reference[Adapted from Andrew Ng's "Applied Bias-Variance for Deep Learning Flowchart" for building better deep learning systems, http://www.computervisionblog.com/2016/12/nuts-and-bolts-of-building-deep.html] --- class: center, middle ## Questions?